Dans la gestion de la crise actuelle, la place accordée aux technologies du numérique a été au cœur de nombreux débats. En particulier, la question de l’accès aux données personnelles est devenue centrale dans les échanges autour du traçage des contacts et du partage des données de santé. Mais la crise a également révélé des fragilités majeures dans notre politique de gestion de ces données, en questionnant notamment l’attribution de la plateforme des données de santé à l’entreprise Microsoft. En outre, la crise a accéléré le recueil et l’exploitation de ces données, sans prendre en compte les conséquences futures de cette captation.
Il devient ainsi impératif de se poser la question des répercussions à long terme des décisions prises aujourd’hui. Il faut également nous interroger sur les grands enjeux qui se cachent derrière nos choix numériques afin de mieux lancer les chantiers de long terme que nous impose ou que devrait nous imposer aujourd’hui la géopolitique du numérique.
Introduction
Nos données numériques apportent quantité d’informations sur nous-mêmes, mais aussi sur l’état de notre société, sur ses atouts et ses fragilités. Derrière des applications anodines circulent en effet des données sur l’état de santé de la population, des indices sur sa réalité sociale, sur l’état de ses infrastructures routières ou encore des informations, parfois sensibles, sur ses activités économiques et politiques. Selon l’usage que l’on fait de ces informations, l’impact sur la société peut être bénéfique ou néfaste. La mathématicienne Cathy O’Neil nous alerte par exemple sur l’usage des données dans l’éducation, la justice en passant par le commerce ou la santé, les organismes sociaux ou les assurances[1]. Les données de santé sont par exemple un trésor pour les compagnies d’assurance qui, si elles y accèdent, peuvent définir des profils de clients à risque pour adapter leur proposition commerciale, accentuant ainsi certaines inégalités face à la santé. C’est pourquoi il ne faut pas prendre à la légère les enjeux qui se cachent derrière le numérique et la circulation des données.
Par ailleurs, ces données sont aussi la matière première des technologies d’apprentissage automatique, souvent regroupées autour du terme « intelligence artificielle », et sur lesquelles reposent de nombreuses innovations technologiques telles que la reconnaissance faciale ou la voiture autonome. Les entreprises et les États trouvent un intérêt évident dans la course à ces données massives qu’ils peuvent utiliser pour développer des technologies de pointe dédiées à des secteurs variés, tels que le contrôle aux frontières, la sécurité, la santé, la justice ou le militaire. Dans le domaine de la santé, au cœur de cette note, les données sont nécessaires si l’on souhaite développer les technologies de machine learning qui permettent d’accompagner la recherche médicale et d’améliorer les outils des praticiens. À ce titre, elles sont déterminantes dans le développement de ce tissu industriel. Mais elles sont aussi éminemment stratégiques : la surveillance des données de santé à l’échelle d’un pays donne une carte d’identité précieuse qui révèle les fragilités d’un système de santé, celles des individus, et permet d’orienter des décisions économiques, politiques voire militaires. La Direction générale de la sécurité intérieure (DGSI) alertait d’ailleurs, dès 2018, sur l’acquisition par les entreprises américaines de plusieurs sociétés françaises expertes dans le traitement de ce type d’informations, et notamment la branche dédiée à la gestion des données clients et stratégiques de Cegedim, acquise par IMS Health en 2015. L’administration s’inquiétait alors de la captation, par « des entités tant publiques que privées », d’informations stratégiques et orientant la politique économique des États-Unis vis-à-vis des industries françaises[2]. Un an plus tard, Microsoft Azure fut désigné, sans passage par un appel d’offre, comme prestataire principal de la Plateforme des données de santé des Français, baptisée Health data hub[3]. Cet hébergeur, qui propose également des services d’analyse, accélère sa captation de données dans l’urgence de la crise sanitaire.
En matière de géopolitique des données, la gestion de la crise actuelle agit ainsi comme un formidable révélateur de notre dépendance extérieure dans le domaine du numérique appliqué à la santé. Face aux enjeux d’indépendance numérique et de protection des données qui se posent, de grands et longs chantiers seront nécessaires. Cette note propose d’apporter quelques pistes de réponses sur la manière de les engager.
1. Penser le numérique relève d’une approche transversale qui s’applique à l’analyse de la gestion des données numériques en santé
Penser le numérique, notamment dans un secteur aussi essentiel et structurant que la santé, nécessite une approche transversale qui prenne en compte plusieurs couches de l’activité numérique. En 2016, la politologue Frédérick Douzet proposait trois « couches du cyberespace » : la couche physique, logique et sémantique[3]. Le schéma ci-dessous s’inspire de ce modèle, mais propose un échelonnage à quatre niveaux des technologies, hiérarchisées selon leur rôle dans l’activité numérique :
- les socles matériels sans lesquels aucune activité numérique n’est possible, composés des infrastructures mais aussi du matériel informatique et mobile ;
- les applicatifs codés, c’est à dire les OS, les logiciels ou les algorithmes, les sites internet, les applications ;
- les données dont les flux circulent entre applicatifs et socles ;
- les usages, qui définissent les manières de vivre dans et avec le numérique.
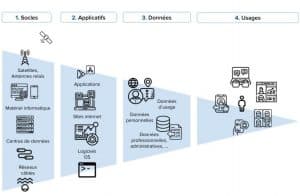
Cette approche transversale donne une place particulière à la dimension matérielle, dans un domaine où très souvent le virtuel et le vocabulaire qui l’accompagne, du cloud au data lake, fabrique un imaginaire qui donne l’impression d’un effacement des frontières physiques et géographiques. Comme l’énonce Amaël Cattaruzza, « les processus de datafication nous obligent à modifier nos approches et nos interprétations et à reconsidérer le concept clef de la géopolitique, à savoir le territoire »[4]. Ainsi, ce n’est pas parce que nos données sont numériques qu’elles ne suivent pas un parcours, qu’elles n’ont pas un lieu de production et de destination, et que les enjeux de leur captation ne renvoient pas à des réalités géopolitiques.
Or, la stratégie numérique en matière de données de santé concerne chacune de ces couches. Elle pose d’abord la question des socles matériels, qui correspond à la « couche physique » de Douzet, c’est-à-dire ce « que l’on peut géolocaliser et dessiner sur une carte ». Ces socles posent la question de la réalité matérielle des données de santé, à savoir leur lieu de conservation et la propriété des serveurs dans lesquels elles circulent. Cette réalité physique concerne à la fois les acteurs principaux, c’est-à-dire ceux qui captent la donnée au départ, et les acteurs secondaires comme les sous-traitants qui récupèrent et exploitent la donnée dans un second temps.
Les applicatifs sont également une couche essentielle au recueil des données de santé au travers de logiciels ou d’applications. Ces outils numériques sont la « couche logique » qui détermine la récolte et la route qui sera prise par les données. Selon les choix effectués par le concepteur du produit numérique, les applicatifs peuvent être plus ou moins gourmands en données, et plus ou moins sécurisés.
Les données de santé sont les contenus que nous produisons, qui portent un sens, une sémantique de notre utilisation des applicatifs. Elles ne sont pas de simples informations qui transitent d’un point à l’autre de l’architecture technique. Elles doivent respecter certaines normes d’écriture, par exemple les procédés d’anonymisation.
Enfin, les usages correspondent à nos pratiques numériques en tant que telles. Elles sont régies par des normes et habitudes d’utilisation des outils numériques, qui fondent la production des données et leur captation, et sur lesquelles les négociations juridiques et les stratégies commerciales reposent. Aujourd’hui, la captation des données dans les usages se traduit par la demande de consentement sur laquelle repose généralement le droit en matière de numérique. Cette autonomisation progressive du droit dans l’industrie du numérique accentue l’importance accordée à cette échelle.
À travers l’exemple des données de santé, nous allons parcourir ces différentes couches mais nous laisserons volontairement de côté certains aspects pourtant essentiels, comme la réalité matérielle des flux de données et l’infrastructure qui la sous-tend, sur lesquels d’autres travaux de l’Institut porteront prochainement.
2. Les données de santé des Français hébergées chez Microsoft Azure : un abandon de souveraineté préjudiciable
La manière dont nous avons délibérément confié nos données de santé à une grande entreprise américaine révèle les failles et les impensés de notre stratégie numérique, ainsi que notre absence d’indépendance réelle dans ce domaine. À l’origine, le Health data hub a pour objectif de rendre les données issues des systèmes d’information des organismes de santé publique plus facilement accessibles aux acteurs privés et aux instituts de recherche médicale. Il centralise ainsi l’ensemble des données préalablement récoltées par le Système national des données de santé (SNDS)[5], et l’enrichit d’autres sources de données telles que celles provenant des dossiers des patients des établissements de santé ou de la médecine de ville. Depuis le 11 mai 2020, la plateforme est également autorisée à réceptionner les données de recensement des malades du COVID-19[6]. Microsoft Azure a ainsi accéléré son processus de récolte de données pendant la crise sanitaire[7].
Ce transfert a suscité de nombreuses oppositions. En premier lieu, les opposants au projet s’inquiètent notamment de la législation américaine en matière d’accès aux données. En effet, le Clarifying lawful overseas use of data act (CLOUD Act)[8], adopté le 23 mars 2018, donne un cadre légal à la saisie de données électroniques localisées dans les serveurs de sociétés américaines hébergées hors de son territoire dans le cas d’une enquête menée par les forces de l’ordre. Cette loi permet ainsi de contourner les traités d’entraide judiciaire en matière pénale (MLAT) relatifs au transfert de données extraterritoriales en proposant des procédures plus légères par la mise en place d’accords internationaux. Ces demandes peuvent par ailleurs faire l’objet d’ordonnances de secret, les gag orders, qui interdisent à l’entreprise d’informer son client de la captation de ses données. Autrement dit, les États-Unis pourraient avoir accès, dans un cadre encore mal défini, à des données de santé de citoyens français sans que ceux-ci n’aient donné leur accord.
En Europe, nous répondons à ces pratiques par le Règlement Général sur la Protection des Données (RGPD)[9] mais la protection qu’il offre semble bien limitée. Par exemple, celui-ci prévoit des conditions dérogatoires qui ont récemment été validées pour l’utilisation des données de santé en temps de crise sanitaire[10]. Par ailleurs, le RGPD repose en grande partie sur le principe de consentement, alors même que l’utilisateur numérique n’est pas informé des conséquences sur le long terme des captations massives de données par une entreprise ou un État.
Enfin, un autre sujet d’inquiétude repose sur le développement de technologies d’avenir à partir des données massives de santé qui ne profiteront pas au territoire où sont recueillies ces données et qui pourraient même avoir des effets néfastes sur les individus ayant confié leurs données. La confiance accordée à ces acteurs économiques doit en effet être mesurée au regard des obligations qui les lient au Gouvernement américain. Dans une situation où il faudrait choisir entre les intérêts des États-Unis et ceux d’autres pays, quels choix feraient Microsoft, Google, Facebook, Amazon si le gouvernement américain leur réclamait la transmission de données stratégiques sur d’autres pays ou entreprises ? Rappelons-nous que les acteurs privés ont un rôle déterminant en temps de guerre, ainsi que le rappelle l’exemple de l’entreprise Michelin pendant la seconde guerre mondiale : si l’usine pneumatique équipait en pneus l’occupant allemand, l’entreprise fournissait dans le même temps aux alliés ses guides, ancêtres de Google Maps comprenant les cartes et les plans des villes.
Pour toutes ces raisons, il est essentiel de conserver la maîtrise de nos données de santé. Nous possédons d’ailleurs les instruments nécessaires à la sélection d’un prestataire sécurisé. L’un des instruments clefs est le référentiel d’exigence français SecNumCloud délivré par l’Agence nationale de la sécurité des systèmes d’information (ANSSI) qui permet de valider la sécurité d’un hébergeur dédié au stockage de données stratégiques. En matière de données de santé, le RGPD est aussi complété par la certification européenne Hébergeurs de données de santé (HDS). L’association de ces référentiels pourrait garantir, dans un premier temps, la fiabilité d’un acteur et sa capacité à répondre aux enjeux sécuritaires. L’hébergement du Health data hub et des services associés devrait ainsi être confié à un acteur qui respecte à la fois le référentiel national de l’ANSSI SecNumCloud, le RGPD et la certification HDS. Ces acteurs existent : des prestataires tels que Oodrive, Outscale ou encore OVH pourraient répondre aux besoins immédiats et intégrer les mêmes outils d’analyse open source installés sur les bureaux virtuels de Microsoft Azure[11]. Cette démarche serait un premier pas vers l’ambitieux projet de cloud souverain, baptisé « cloud de confiance » en octobre 2019[12].
Proposition 1 : réserver l’hébergement du Health data hub et des services associés à un acteur certifié SecNumCloud et HDS.
À ce stade, force est de constater que la gestion française des données numériques de santé est emblématique de notre manière de considérer ces technologies : envisagée comme un simple outil pratique, l’informatique est trop souvent sous-estimée et déléguée à la première occasion. Cette suite de décisions politiques et économiques fragilisent à long terme nos capacités à assurer notre indépendance numérique. Finalement, nous tentons de répondre aux monopoles des géants du secteur et à des pratiques intrusives de captation de données par des tentatives de réglementations européennes et nationales qui semblent malheureusement fragiles face aux intérêts des entreprises et des États. La crise actuelle alerte une fois de plus sur la nécessité de remettre en cause nos dépendances à ces acteurs exclusifs. Elle pose également la question de la protection des données personnelles, face à laquelle nous sommes encore sous-armés.
3. La sous-traitance permise par le Règlement général de protection des données (RGPD) pose la question délicate du recoupement des données
Les données de santé peuvent révéler des informations sensibles et qui peuvent s’avérer nuisibles pour les individus, c’est pourquoi elles bénéficient d’un traitement particulier afin d’assurer au mieux leur confidentialité. Mais la crise actuelle a remis au goût du jour les problèmes bien connus en matière d’anonymisation des données, notamment à travers le principe de pseudonymisation. En effet, il est possible de démontrer que celui-ci ne mène pas à une anonymisation réelle des données, et qu’il reste possible de retrouver a posteriori une identité par le recoupement de données tierces. Ainsi, l’association de l’âge, des dates et lieux d’hospitalisation, des remboursements médicaux, des prescriptions, à un même « pseudonyme » rend l’identification possible par le chaînage des données. Cette réalité technique est connue et mentionnée par la Commission nationale de l’informatique et des libertés (CNIL)[13].
Dans quels cas pourraient avoir lieu ces recoupements ? Ce principe est déjà rendu possible en centralisant ces données dans les serveurs Microsoft, qui dispose par ailleurs d’informations tierces au travers d’une multitude d’outils numériques. Mais il pourrait aussi advenir, par exemple, lors du croisement de données issues d’autres hébergeurs autorisés à l’exploitation et à la récolte des données de santé via la certification HDS mentionnée précédemment. En effet, le RGPD considère qu’un sous-traitant bénéficiant d’une certification approuvée au niveau européen apportent les « garanties suffisantes » à la récolte et l’usage des données[14]. La certification HDS délivrée par l’Association française de normalisation (Afnor) mais aussi un ensemble de cabinets d’organismes certifiants[15] a déjà été obtenue par un grand nombre de géants du numérique parmi lesquels Google Cloud Services, Amazon Web Service, IBM Iaas, Boston scientific corporation ou Accenture[16]. Le schéma ci-dessous montre ainsi les nombreuses passerelles potentielles entre le Health data hub et des sous-traitants certifiés HDS : si un acteur utilisant la plateforme des données de santé, privé ou public, sous-traite une partie du cheminement ou de l’analyse de ces données à une entreprise certifiée HDS, il permet à ces prestataires de recueillir ces données.
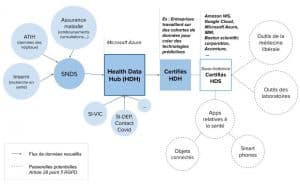
Or, ces géants du secteur collectent également des données personnelles au travers de leurs applications, certaines étant également des données de santé que produisent des outils comme Fitbit appartenant à Google. Le recoupement des données est ainsi possible lorsque plusieurs critères concordent, tel que l’âge, le lieu d’habitation, les déplacement horodatés sur le lieu d’hospitalisation. En outre, on constate que l’accès à la plateforme des données de santé est conditionné par la validation d’un dossier envoyé en réponse aux appels d’offre du Health data hub[17]. Cependant, le cadre technique à respecter n’est pas précisé et ne comprend pas la documentation complète des sous-traitants techniques. Pourtant, les « passerelles » potentielles sont nombreuses entre ces acteurs.
Ce problème révèle donc le manque de prise en compte de la complexité des réseaux informationnels dans les décisions politiques. Ainsi, si la réglementation européenne et ses mécanismes de certification représentent un danger pour la conservation et l’exploitation de nos données, alors une réponse nationale est nécessaire. Le sous-traitant n’étant pas un acteur minoritaire, la sécurité de nos systèmes d’information et de nos données dépend également de ces prestataires tiers. C’est pourquoi l’étude approfondie des dépendances aux sous-traitants devrait être une condition obligatoire de tout appel d’offre public, quelque soit le domaine d’application.
Proposition 2 : l’étude approfondie des dépendances à des sous-traitants devrait être une condition obligatoire de tout appel d’offre public portant sur une prestation numérique, quelque soit le domaine d’application.
Par ailleurs, une réponse juridique devrait être apportée pour encadrer l’usage des mécanismes de certification par la sous-traitance et imposer au niveau national le respect d’une réglementation supplémentaire. Cette législation nationale pourrait être, dans un premier temps, les référentiels en matière de cybersécurité de l’ANSSI.
Proposition 3 : conditionner la certification HDS dans le cadre de la sous-traitance au respect des référentiels de l’ANSSI en matière de cybersécurité.
4. Le principe de consentement, privilégié aujourd’hui, impose de délivrer une information juste à l’utilisateur
Le consentement est présenté comme la solution aux conflits de droits en matière de captation de données numériques. Ainsi, dans la plupart des cas, à partir du moment où l’utilisateur donne son accord à l’entreprise qui récolte ses données selon les conditions d’utilisation, l’entreprise qui conserve ces informations est dans la légalité pour leur stockage et leur exploitation. Mais ce principe de consentement a ses limites. Car comme nous l’avons vu, le numérique est un sujet transversal qui comporte de nombreuses échelles et une multitude d’acteurs visibles et invisibles, et dans ce cadre les actions futures sur les données captées ne peuvent être déterminées au moment du consentement. Afin de faire du consentement une démarche éclairée, il apparaît nécessaire d’aider l’utilisateur à comprendre les enjeux de l’exploitation des données.
Dans un premier temps, la démocratisation de l’hygiène numérique, pratiques réservées aujourd’hui aux métiers de la sécurité et de la défense, nous paraît essentielle. Il serait par exemple opportun de généraliser l’apprentissage d’une hygiène numérique dans les écoles et les entreprises. Ainsi, le projet CyberEdu initié en 2013 par l’ANSSI pour une éducation à la cybersécurité dans les écoles ne doit pas être une option mais un enseignement à part entière. Ces pratiques cybersécuritaires sont aujourd’hui réservées aux métiers de la défense, et ont été notamment encadrées par la directive sur la sécurité des réseaux et des systèmes d’information (SRI), première législation européenne sur la cybersécurité[18]. Une équivalence à la directive SRI pourrait ainsi être adaptée au domaine de la santé.
Proposition 4 : généraliser l’apprentissage d’une « hygiène numérique » dans les écoles et les entreprises.
Proposition 5 : un équivalent adapté au secteur particulier de la santé de la directive sur la sécurité des réseaux et des systèmes d’information (SRI) permettrait de mieux encadrer, protéger et sensibiliser sur les pratiques spécifiques autour des données de santé.
Enfin, le choix même des équipements et applicatifs doit pouvoir faire l’objet d’une décision éclairée, et pour lequel le consommateur numérique n’a aujourd’hui que trop peu d’informations. Afin de rendre ces choix plus transparents, il est important de comprendre comment l’objet numérique a été conçu, ses caractéristiques en matière de sécurité, ou encore les intérêts portés par les acteurs qui interviennent dans son exploitation. Rendre visible ces informations aujourd’hui difficiles à percevoir pour le non-initié est la condition sine qua non pour un usage éclairé des technologies numériques.
Proposition 6 : rendre visible les caractéristiques d’un produit numérique en matière de sécurité, les différents acteurs intervenant dans sa conception et son exploitation, ainsi que les risques potentiels sur le court et le long terme.
Conclusion
La crise actuelle, au travers des manœuvres qui entourent les données de santé, met en avant nos dépendances à une minorité d’acteurs du numérique souvent étrangers et dépendants d’autres législations. Cette monopolisation est peu considérée par le citoyen comme par le politique alors qu’elle fragilise sur le court et le long terme des secteurs privés et publics essentiels au bon fonctionnement de la société. Si notre exposé sur l’exploitation des données de santé se limite ici essentiellement à notre dépendance vis-à-vis d’entreprises américaines, d’autres États développent des stratégies agressives en matière de numérique. Par exemple, la Chine et la Russie investissent massivement dans des infrastructures numériques souveraines et dans des politiques de conservation de leurs données. Ainsi, il n’est plus excessif de parler de cyberguerre, dans un contexte de guerre commerciale, de course à la connaissance et de développement technologique qui opposent les grandes puissances de ce monde.
Nous avons pourtant nous aussi des moyens d’agir, ainsi que nous l’avons vu, et nous devons prendre conscience de la nécessité de renforcer ce qui existe déjà. Cela nécessitera des moyens et des législations plus ambitieux que ceux qui existent à l’heure actuelle. C’est pourquoi tout doit être considéré dans le processus de transmission des informations : des câbles sous-marins au matériel local, des lignes de codes au principe de security by design des produits numériques.
[1] Cathy O’Neil, Weapons of Math Destruction, édition Crown books, 2016.
[2] Direction Générale de la Sécurité intérieure (DGSI), « Panorama des ingérences économiques américaines en France », avril 2018, rendue partiellement publique par Le Figaro et retranscrite par Gérard Streiff sur le site Cause commune.
[3] Le vent se lève, Le Health data hub, ou le risque d’une santé marchandisée, 18 avril 2020.
[3] Frédérick Douzet, Le cyberespace, un enjeu majeur de géopolitique, La revue des médias, 2016.
[4] Amaël Cattaruzza, Géopolitique des données numériques, Pouvoir et conflits à l’heure du Big Data, Éditions Le Cavalier Bleu, 2019, p.142.
[5] Le SNDS réunit depuis 2016 les données du SNIIRAM (le Système national d’information interrégimes de l’Assurance Maladie), de l’Institut national de la santé et de la recherche médicale (Inserm) et l’Agence technique de l’information sur l’hospitalisation (ATIH).
[6] La loi du 11 mai 2020 prorogeant l’état d’urgence sanitaire prévoit que le Health Data Hub intègre les données du fichier SI-DEP (système d’information national de dépistage populationnel) qui regroupe les données des laboratoires et le fichier Contact-Covid qui rassemble les enquêtes épidémiologiques réalisées par les brigades sanitaires.
[7] Legifrance, 23 mars 2020, le Health data hub est mentionné sous son nom français comme « plateforme technologique du groupement d’intérêt public » dans la version en vigueur au 9 mai 2020 de l’Arrêté du 23 mars 2020 prescrivant les mesures d’organisation et de fonctionnement du système de santé nécessaires pour faire face à l’épidémie de covid-19 dans le cadre de l’état d’urgence sanitaire.
[8]115th Congress, 6 février 2018, S.2383 – CLOUD Act
[9] EUR-Lex, 27 avril 2016 entré en vigueur le 25 mai 2018, Règlement (UE) 2016/679 du Parlement européen et du Conseil du 27 avril 2016 relatif à la protection des personnes physiques à l’égard du traitement des données à caractère personnel et à la libre circulation de ces données, et abrogeant la directive 95/46/CE (règlement général sur la protection des données).
[10] Sur ce sujet, voir la Lettre de Andrea Jelinek, Présidente du Comité européen de la protection des données, à Mark Libby, Chef de mission adjoint au Département d’État américain pour la mission américaine auprès de l’Union européenne, le 24 avril 2020.
[11] L’un des outils utilisés est jupyter, un « pack » open source que Microsoft a intégré à sa plateforme et dont il récupère les données produites.
[12] L’usine nouvelle, 7 avril 2020, Le « cloud de confiance” fera-t-il mieux que le « cloud souverain » français ?
[13] Informations relatives à l’anonymisation sur le site de la CNIL.
[14] Point 5 de l’article 28 relatif à la sous-traitance : « un mécanisme de certification approuvé comme le prévoit l’article 42 peut servir d’élément attestant de l’existence des garanties suffisantes ».
[15] Liste des organismes certifiants disponible sur le site esante.gouv.fr.
[16] Liste complète des hébergeurs certifiés HDS sur le site esante.gouv. À noter que Google Cloud Services, Amazon Web Services et IBM sont tous passés par le cabinet Bureau Veritas pour leur certification.
[17] Appel à projets « L’intelligence artificielle pour une expérience améliorée du système de santé » lancé par le Health Data Hub du 20 décembre 2019 au 1er juin 2020.
[18] Commission européenne, The Directive on security of network and information systems (NIS Directive), juillet 2016.
Vous avez apprécié cette publication ?